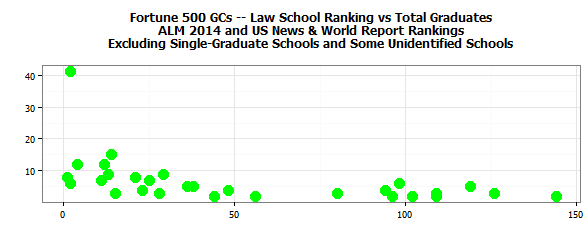
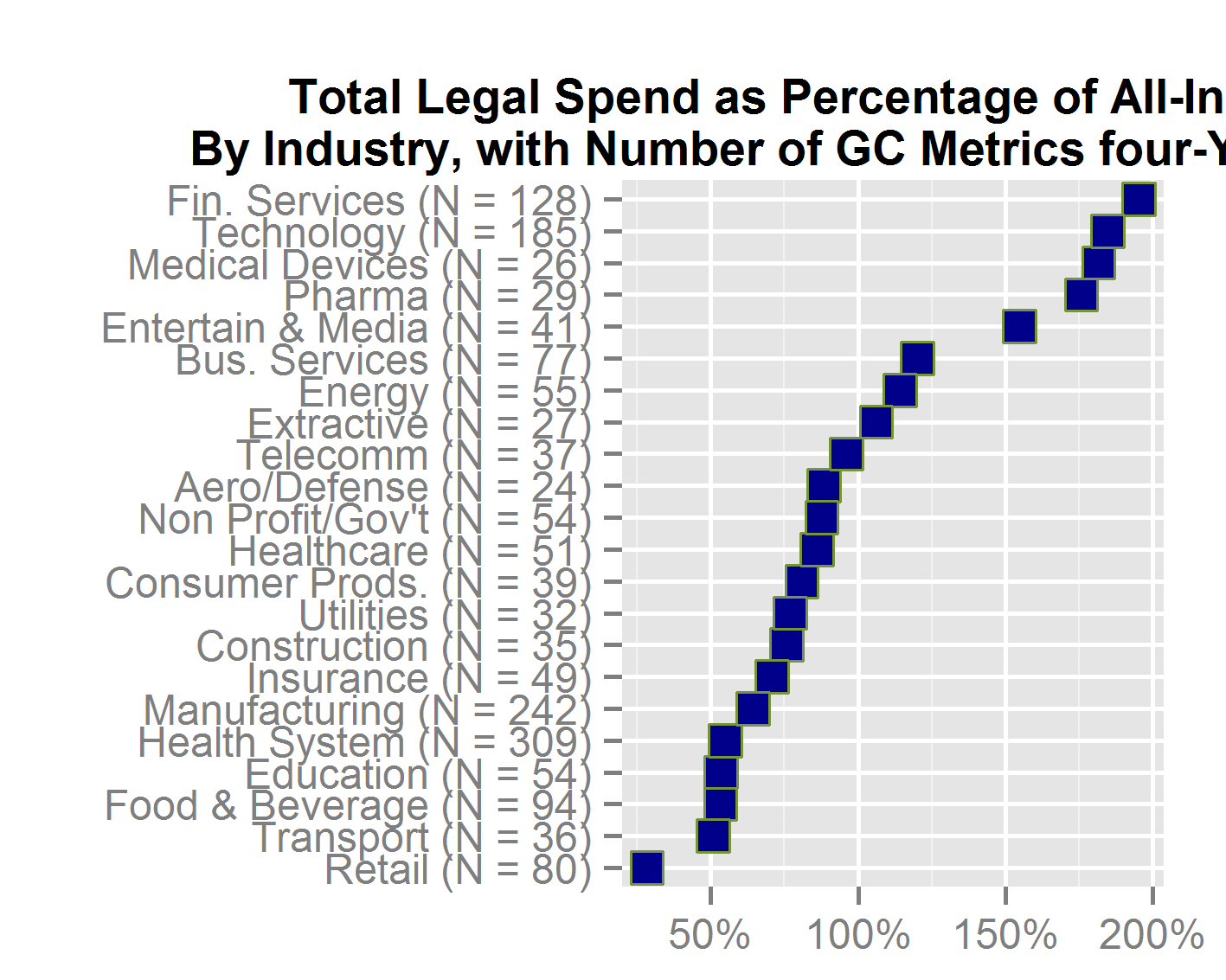
A precept of reproducible research, such as survey results that allow readers to understand the methodology and credibility of the findings, is to make generous use of “N = some number”. That conventional shorthand for “how many are we talking about” shows up in almost every reproducible-research graphic. Whether in the title of a plot, the text that relates to it, on the plot itself or in a footnote, a reader should always be quickly able to learn how many respondents answered each question or how many documents were reviewed or how many law departments had a given benchmark, or whatever pertains to the topic of the plot.
The larger the N, the more reliable the averages or medians that result from the data. For example, if the “average base compensation of general counsel” rose 2% from one year to the next, it makes a huge difference whether that change applies to N = 8 [general counsel] or N = 80. Changes in small numbers of observations have much less credibility than changes in large numbers.